None .. An html document created by ipypublish
outline: ipypublish.templates.outline_schemas/rst_outline.rst.j2 with segments: - nbsphinx-ipypublish-content: ipypublish sphinx content
11. Sujets de projet pour l’évaluation¶
Basile Marchand (Centre des Matériaux - Mines ParisTech/CNRS/Université PSL)
11.1. Modalités d’évaluation¶
Le projet est à réaliser en binôme. L’évaluation de ce projet est décomposée en deux parties :
Analyse du code que vous réaliserez. Les critères d’évaluation sont les suivants :
Clareté et lisibilité du code
Documentation du code
Généricité du code (doit pouvoir fonctionner avec d’autres jeux de données)
Soutenance présentation en binome d’approximativement 15 minutes plus 10 minutes de questions
Les dates importantes sont les suivantes :
10/11/2020 avant 12h00 : Envoi du code par mail à l’adresse basile.marchand@mines-paristech.fr
12/11/2020 soutenances
11.2. Analyse d’un essai de traction¶
11.2.1. Description du sujet :¶
Module d’Young
Limite d’élasticité
Contrainte à 0.2% de déformation plastique
Contrainte maximale
Le mode de fonctionnement attendu est le suivant :
L’utilisateur fournit au programme le chemin vers le dossier contenant les données expérimentales à traiter. (Cette saisie utilisateur peut se faire de la manière que vo us voulez)
Le programme construit la courbe de traction (contrainte, déformation)
Le programme construit la courbe de traction effective (contrainte effective, déformation)
A partir des courbes précédentes identifier les paramètres matériaux demandés précédémment.
Synthétiser les résultats dans un affichage Python “jolie”.
Les données à utiliser peuvent être téléchargées à l’adresse suivante http://bmarchand.fr/cours/sgm/projet1.tar.gz
11.2.2. Indications :¶
Pour lire une image le code à utiliser est le suivant :
from skimage.io import imread, color
image = imread( "data/image_00.png", as_grey=True)
11.3. Propagation de fissure¶
11.3.1. Description du sujet :¶
L’objectif de ce projet est de mettre en place un programme Python permettant à partir de cette ensemble de données :
Identifier les paramètres d’un modèle de propagation de fissure (le modèle est fourni plus loin)
Utiliser le modèle identifié pour simuler l’avancée d’une fissure.
Le mode de fonctionnement attendu est le suivant :
L’utilisateur fournit au programme le chemin vers les fichiers expérimentaux. (Cette saisie utilisateur peut se faire de la manière que vous voulez)
Le programme identifie les paramètres du modèle pour les différents essais.
Le programme calcul l’évolution de \(a(N)\) en utilisant les différents paramètres identifiés à la question 2.
Synthétiser les résultats dans un affichage Python “jolie”.
Les données à utiliser pour ce projet peuvent être téléchargée à l’adresse suivante http://bmarchand.fr/cours/sgm/projet2.tar.gz
11.3.2. Indications¶
Le modèle de propagation de fissure considéré dans ce projet est celui développé dans [Maurel2009]. Une version pdf de l’article vous est fournie dans le dossier data.
Les paramètres du modèle à identifier sont donc les quatre scalaires \(\gamma_e\) \(\gamma_p\) \(m_e\) et \(m_p\)
[Maurel2009] V. Maurel, L. Rémy, F. Dahmen, N Haddar, An engineering model for low cycle fatigue life based on a partition of energy and micro-crack growth, International Journal of Fatigue, 2009.
11.4. Réaction-diffusion : modèle de Gray-Scott¶
11.4.1. Description du sujet :¶
L’objectif de ce projet est de mettre en place un programme Python permettant de simuler un phénomène de réaction-diffusion de deux espèces en considérant le modèle de Gray-Scott.
Le mode de fonctionnement attendu est le suivant :
L’utilisateur fournit au programme les paramètres d’entrée du problèmes (coefficients du modèle, taille de la zone simulée, temps de simulation. (Cette saisie utilisateur peut se faire de la manière que vous voulez : saisie à la console, lecture d’un fichier texte, …)
Le programme réalise la simulation
Le programme génère tous les x incrément de temps (x à définir comme vous le souhaitez) une image représentant les concentrations des espèces à cet instant.
Synthétiser les résultats dans un affichage Python “jolie”.
11.4.2. Indications 1:¶
Le modèle de réaction diffusion considéré dans ce projet est celui de Gray-Scott [GrayScott1983].
Avec :
\(u\) et \(v\) les concentrations des espèces U et V
\(r_u\) et \(r_v\) les coefficients de diffusion des espèces U et V
\(k\) et \(f\) sont des coefficients de réaction des espèces chimiques
La réaction chimique associée à ce modèle est la suivante :
11.4.3. Indications 2:¶
Le problème à résoudre est donc de déterminer l’évolution de \(u(x,y,t)\) et \(v(x,y,t)\). Pour cela il faut résoudre le système d’équations aux dérivées partielles suivant :
Pour cela il va falloir mettre en place une résolution par différences finies. La méthode des différences finies consiste :
Définir une discrétisation (spatiale et temporelle dans ce cas)
Approximer les dérivées partielles à l’aide des différences finies, dans le cas de ce projet on peut donc écrire.
A partir des formules précédentes et en les ré-injectant dans le système d’équations à résoudre on peut facilement déterminer l’expression d’un système pouvant être réso lu numériquement.
Pour la résolution du problème vous êtes invité à utiliser les jeux de paramètres suivants :
\(r_u\) |
\(r_v\) |
\(f\) |
\(k\) |
|---|---|---|---|
0.16 |
0.08 |
0.035 |
0.065 |
0.14 |
0.06 |
0.035 |
0.065 |
0.16 |
0.08 |
0.06 |
0.062 |
0.10 |
0.10 |
0.018 |
0.050 |
0.10 |
0.16 |
0.020 |
0.050 |
0.16 |
0.08 |
0.05 |
0.065 |
0.16 |
0.08 |
0.035 |
0.060 |
Enfin vous remarquerez que je n’ai donné aucune indications concernant les conditions initiales du problème, i.e. les concentrations d’espèces à l’instant \(t=0\). Je laisse libre cours à votre imagination.
Dernière indication : Le modèle de Gray-Scott étant très classique vous pouvez très facilement trouver sur internet un programme Python faisant ce qui est attendu. Vous pouvez regarder mais il est cependant très fortement déconseillé de faire un copier-coller et d’espérer que je ne m’en rendrais pas compte.
[GrayScott1983] P. Gray, S.K. Scott. Autocatalytic reactions in the isothermal, continuous stirred tank reactor: isolas and other forms of multistability, Chem. Eng. Sci., 1983.
11.5. Plus court chemin¶
11.5.1. Description du sujet :¶
L’objectif de ce projet est de mettre en place un programme Python permettant de déterminer le plus court chemin entre deux stations de métro dans Paris.
Le mode de fonctionnement attendu est le suivant :
L’utilisateur fournit au programme son point de départ et sa destination
Le programme charge la liste des lignes de métro
Le programme détermine le trajet optimal
Synthétiser les résultats dans un affichage Python “jolie”.
11.5.2. Indications 1¶
La définitions des lignes de métro est à faire par vous-même. Deux approches sont envisageables :
11.5.2.1. Solution 1 : Fichier texte¶
Vous définissez les lignes de métro dans un fichier texte de la forme suivante :
Ligne 1
Chateau de vincennes
Berault
...
La Defense
Ligne 2
...
11.5.2.2. Solution 2 : plus jolie¶
Vous faites un requète via Python pour accéder à l’adresse https://api-ratp.pierre-grimaud.fr/v4/stations/metros/1 par exemple pour récupérer les stations de la ligne 1.
11.5.3. Indication 2¶
Pour déterminer le plus court chemin la solution la plus simple est de se baser sur la notion de Graphe et d’utiliser l’algorithme de Dikjstra. Je précise que cette algorithme est très classique donc très bien documenter sur internet. Vous pouvez également trouver des code python déjà fait. Mais attention si vous faites du copier-coller sans comprendre je le verrai très rapidement.
11.5.4. Indication 3¶
Pour le calcul du plus court chemin, plus court en terme de temps, vous pouvez faire l’hypothèse que le temps de trajet entre deux stations est identique (2 minutes) pour toutes les lignes et toutes les stations
11.6. Le jeu de la vie¶
11.6.1. Description du sujet :¶
Le principe est le suivant : On se donne une grille de taille \(N\times N\). Chaque case de la grille représente une cellule pouvant être uniquement dans deux états : (i) morte ; (ii) vivante. Chaque cellule possède 8 voisins, les cellules de bords vérifient des conditions de périodicités. Pour passer de la génération \(k\) à la génération \(k+1\) les règles d’évolutions des cellules sont les suivantes :
Si une cellule vivante à la génération \(k\) est entourée de 2 ou 3 cellules vivantes alors elle reste vivante à la génération \(k+1\) sinon elle devient morte.
Si une cellule morte à la génération \(k\) est entourée par exactement 2 cellules vivantes alors elle devient vivante à l’itération \(k+1\).
Le mode de fonctionnement attendu est le suivant :
L’utilisateur fourni les données d’entrée : (i) taille de la grille ; (ii) motif initial parmis une collection de motif disponibles ; (iii) nombre de génération à calculer.
Le programme réalise l’ensemble des simulations et pour chaque génération génère une image correspondant à l’état des cellules pour cette génération.
A la fin le programme affiche le pourcentage de cellule vivant à la dernière génération.
11.6.2. Indication¶
Les motifs prédéfinis devant exister à minima dans votre programme (vous pouvez en ajouter d’autres), sont les suivant positionnés au centre de la grille initiale.
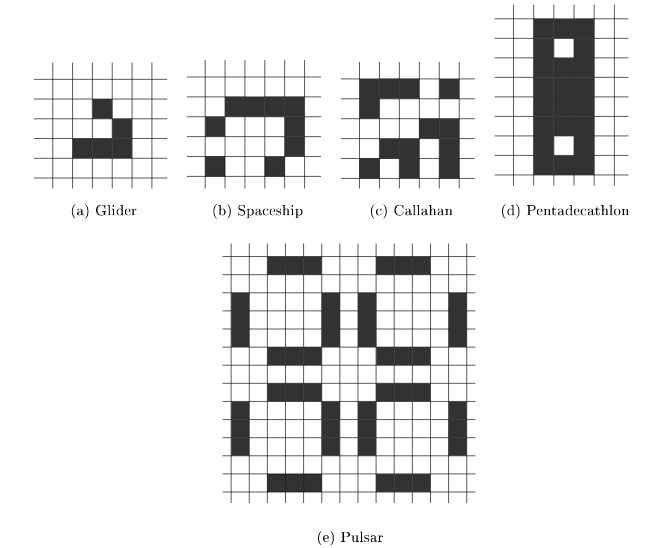
Fig. 11.6.1 media/motif_jeu_de_la_vie.png¶
11.6.3. Bonus¶
Une fois que vous aurez un programme fonctionnel. Si vous le souhaitez (c’est une question bonus) vous pouvez modifier votre programme pour associer différentes couleurs à vos cellules vivantes en suivante la règle suivante :
En rouge les cellules vivantes aux générations \(k-1\) et \(k\) mais qui vont mourrir à la génération \(k+1\)
En vert les cellules qui viennent de naître à la génération \(k\) et vivront encore à la génération \(k+1\)
En jaunce les cellules qui viennent de naître à la génération \(k\) et mourront à la génération \(k+1\)
En noire les cellules vivantes aux générations \(k-1\) et \(k\) et qui seront encore vivantes à la génération \(k+1\)
11.7. Mix énergétique optimale¶
11.7.1. Description du sujet¶
Dans ce sujet on s’intéresse à la répartition optimale pour la production d’énergie en utilisant l’éolien et le solaire. L’objectif est de définir le ratio optimal entre éolien et solaire en prenant en compte l’évolution des saisons au cours de l’année.
Pour cela nous allons définir trois modèles pour approximer les sources d’énergie solaire \(S(t)\) et éolienne \(W(t)\) au cours du temps. Et nous définissons également \(L(t)\) une approximation de la consommation éléctrique du réseau.
Les séries temporelles sont normalisées de la manière suivante \(\langle{W}\rangle = \langle{S}\rangle = \langle{L}\rangle := \frac{1}{T} \int_0^T L(t) d t = 1\). Et on définit :
Tout l’objectif du projet est donc de déterminer le paramètre \(\alpha \in [0,1]\) tel que la fonction d’écart suivante soit minimale
11.7.2. Indication¶
Pour réaliser ce projet il vous faut procéder de la manière suivante :
Identifier le paramètres \(A_W\), \(A_s\), \(A_L\). Pour cela vous avez à disposition à l’adresse http://bmarchand.fr/download/data/projet_mix.zip les données mesurées en Europe sur 4 années consécutives. A vous de proposer une démarche d’identification des paramètres.
Identifier par optimisation le paramètre \(\alpha\) permettant de minimer la fonction de mix énergétique.
Introduire un offset temporelle dans le modèle de source d’énergie éolien
\[ \begin{align}\begin{aligned} W(t) = 1 + A_W \cos \left( \omega t - \phi \right)\\Identifier alors la nouvelle valeur de :math:`\alpha` en fonction de\end{aligned}\end{align} \]\(\phi \in \left[ 0, 2\pi \right]\).
Pour finir on introduit une source d’énergie non-renouvelable constante dans le mix énergétique \(C(t) = 1 - \gamma\) et on définit la nouvelle fonction d’écart
\[ \begin{align}\begin{aligned} \left\langle \left\lbrace \gamma \left[ \alpha W(t) + (1-\alpha) S(t) \right] + C( \gamma ) - L(t) \right\rbrace^2 \right\rangle\\Définir l'évolution de :math:`\alpha` minimisant la fonction écart\end{aligned}\end{align} \]en fonction de \(\gamma\)
11.8. Réseau électrique Européen¶
11.8.1. Description du sujet¶
Dans ce projet nous allons nous intéresser aux productions d’électricité d’une partie des pays Européen. Vous avez pour cela à votre disposition le fichier de données contenant les séries temporelles des “déséquilibre de puissances” pour le mois de Janvier 2017 d’un certain nombre de pays Européen. Les données sont à télécharger à l’adresse suivante http://bmarchand.fr/download/data/projet_reseau.zip
Pour ce projet nous allons donc devoir étudier le graph du réseau électrique Européen. Pour cela nous allons tout d’abord étudier le graph suivant :
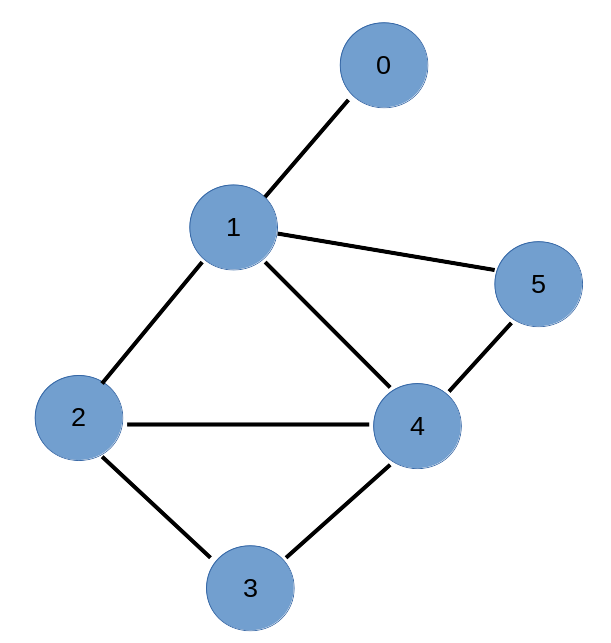
Fig. 11.8.1 ./media/graphes.png¶
Ce graphe se traduit donc par les deux listes suivantes :
[1]:
nodes = [0, 1, 2, 3, 4, 5]
edges = [(0, 1), (1, 2), (1, 4),
(1, 5), (2, 3), (2, 4),
(3, 4), (4, 5)]
11.8.2. Indication¶
Construire la matrice d’adjacence du graphe défini précédemment. En théorie des graphes la matrice d’adjacence est une matrice carrée symétrique. Les éléments de cette matrice indique quelle pair de noeuds sont adjacents dans le graphe.
Déterminer le degré, noté \(k_n\), de chaque noeuds du graphes. En théorie des graphes le degré d’un noeuds correspond au nombre de segment reliant ce noeuds.
Déterminer la matrice d’incidence \(K\) du graphe. On fera l’hypothèse que les segments sont toujours orienté du noeuds de valeur le plus faible vers le noeuds de valeur le plus élevé (noeuds 2 vers 3 et pas 3 vers 2). La matrice d’incidence en théorie des graphes se défini comme une matrice \(n\times m\) avec \(n\) le nombre de noeuds et \(m\) le nombre de segments. Cette matrice est telle que \(k_{ij} = 1\) si $ noeud_i$ et \(segment_j\) sont lié et \(0\) sinon.
Définir le Laplacien du graphe. Le Laplacien du graphe se définit de deux manières différents :
4.1 \(L = K\cdot K^T\)
4.2 La différence entre l matrice diagonale des degrés des noeuds (les \(k_n\) de la question 2 mis sur une matrice diagoname) et la matrice d’adjacence.
Nous allons maintenant identifier les noeuds de notre graphe à certains pays Européen
0=DK, 1=DE, 2=CH, 3=IT, 4=AT, 5=CZ. Le flux de puissance entre les pays peut alors se définir de la manière suivante :\[ \begin{align}\begin{aligned} p_i = \sum_j \tilde{L}_{i,j}\theta_j \qquad \text{et} \qquad f_l = \frac{1}{x_l} \sum_i K_{i,l}\theta_i, \qquad \text{où} \qquad \tilde{L}_{i,j}= \sum_l K_{i,l}\frac{1}{x_l} K_{j,l}\\est la matrice Laplacienne pondérée. Pour simplifier le problème\end{aligned}\end{align} \]nous allons supposer que \(x_l = 1\). A partir des données fournies dans le fichier
imbalance.csvdéterminer les valeurs de \(\theta_j\) pour la première heure du premier janvier 2017 et les valeurs de \(f_l\). On fera pour cela l’hypothèse que \(\theta_0 = 0\).Déterminer le flux de puissance moyen entre pays sur le mois de Janvier 2017.
11.8.3. Bonus¶
Pour information il existe ce qu’il faut en python pour très facilement des morceaux de carte à tout hasard l’europe et tracer des informations dessus….
12. Image segmentation project¶
Image segmentation is widely used in medical and engineering applications. Image segmentation is basically searching specific details in an image. Such details can be the color, shape or size of an objects. Objects are defined by the user.
Image segmentation is used as well in mechanics of materials. The photo below show the inside of an aluminum sample. Stresses were applied on this sample and stopped just before the sample breaks. A large crack has grown inside the sample. In order to observe the crack, the sample was scanned in special microscopes to generate the image below. The crack developped from the coalescence of small black pores. The small pores outside of the crack are to be segmented and counted.
The main goals are:
Put images in the correct order to reconstruct the whole sample. This means that the sample above is constructed from hundreds/thousands of images that are stitched together to form a 2D map.
Use opencv to filter images and segment the black pores. All black pores (almost circular) are to be counted. For each image, a surface fraction of black pores is to be calculated and saved in a text file.
Use machine learning (Convolutional neural network-based algorithms) to exclude foreign objects during segmentation (python libraries to use: tensorflow, kira). Foreign objects could be black scratches or dust. The main crack should not be counted in the segmentation. The black surrounding of the sample should not be counted.
13. Smart bibliography project¶
A smart library is a folder in which articles are saved in sub-folders according to their year of publication. For instance, all articles that are published in 2021 will be saved in a folder named “2021”.
The main goals are: * Find articles written by an author. For example, the program should search in all sub-folders for articles written by “Marchand” if I am interested in this author’s articles.
Find articles that contain one or multiple keywords. For instance, the program will search for articles that contain the keyword “nulear energy” and precise the number of times the keyword shows up in the article (for relevance). The most common library that reads pdfs as text is tika. Here is an example (you can still use another python library that reads/parsers pdf files):
from tika import parser # pip install tika raw = parser.from_file('ShokeirMoghaziOmaraGhazalyEmaraSalem20.pdf') print(raw['content'])
Open a pdf file (not an article) and choose a position on a given page to add your signature.
[ ]: